AlphaCodium¶
Code Generation with AlphaCodium: From Prompt Engineering to Flow Engineering.
Official Implementation:
Tal Ridnik, Dedy Kredo, Itamar Friedman
Abstract¶
Code generation problems differ from common natural language problems - they require matching the exact syntax of the target language, identifying happy paths and edge cases, paying attention to numerous small details in the problem spec, and addressing other code-specific issues and requirements. Hence, many of the optimizations and tricks that have been successful in natural language generation may not be effective for code tasks.
In this work, we propose a new approach to code generation by LLMs, which we call AlphaCodium - a test-based, multi-stage, code-oriented iterative flow, that improves the performances of LLMs on code problems.
We tested AlphaCodium on a challenging code generation dataset called CodeContests, which includes competitive programming problems from platforms such as Codeforces. The proposed flow consistently and significantly improves results. On the validation set, for example, GPT-4 accuracy (pass@5) increased from 19% with a single well-designed direct prompt to 44% with the AlphaCodium flow.
Many of the principles and best practices we acquired in this work, we believe, are broadly applicable to general code generation tasks.
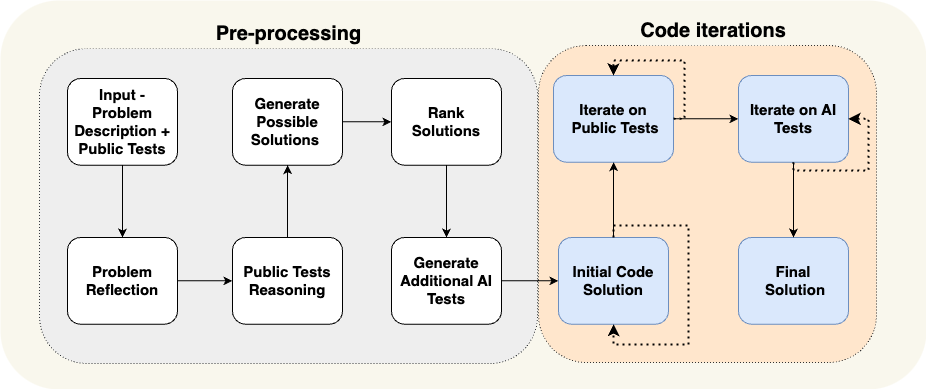
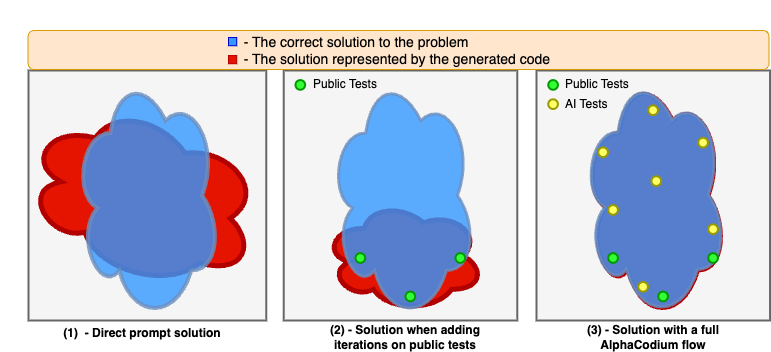
Installation¶
-
setup a virtual environment and run:
pip install -r requirements.txt -
Duplicate the file
alpha_codium/settings/.secrets_template.toml, rename it as.secrets.toml, and fill in your OpenAI API key: -
Download the processed CodeContest validation and test dataset from hugging face, extract the zip file, and placed the extracted folder in the root of the project.
How to run¶
Configuration¶
The file: alpha_codium/settings/configuration.toml contains the configuration for the project.
In the config section you can choose the model you want to use ("gpt-4", "gpt-3.5-turbo-16k", or others).
Solving a specific problem¶
To solve a specific problem with AlphaCodium, from the root folder run:
python -m alpha_codium.solve_problem \
--dataset_name /path/to/dataset \
--split_name test \
--problem_number 0
dataset_name is the path to the dataset folder you downloaded in the installation step.
-
Note that the validation set contains 117 problems, and the test set contains 165 problems, so the
problem_numberparameter should be accordingly (zero-based) -
The
split_namecan be eithervalidortest. -
The following sections in the configuration file:
solve,self_reflection,possible_solutions,generate_ai_tests,initial_code_generation,public_tests,ai_testsenable to adjust possible configurations for the different stages of the flow. -
Each run logs the results to a file named
alpha_codium/example.log. Reviewing the log file is a good way to understand what is going on in each stage of the flow.

Solving the entire dataset¶
to solve the entire dataset with AlphaCodium, from the root folder run:
python -m alpha_codium.solve_dataset \
--dataset_name /path/to/dataset \
--split_name test
--database_solution_path /path/to/output/dir/dataset_output.json
- The
split_namecan be eithervalidortest. database_solution_pathis the path to the directory where the solutions will be saved.- The
datasetsection in the configuration file contains the configuration for the running and evaluation of a dataset. - Note that this is a long process, and it may take a few days to complete with large models (e.g. GPT-4) and several iterations per problem.
dataset.num_iterationsdefines the number of iterations for each problem (pass@K). For a large number of iterations, it is recommended to introduce some randomness and different options for each iteration to achieve top results.
Running the evaluation¶
Once you generate a solution for the entire dataset (valid or test), you can evaluate it by running:
python -m alpha_codium.evaluate_dataset\
--dataset_name /path/to/dataset\
--split_name test\
--database_solution_path /path/to/output/dir/dataset_output.json
Technical Q&A¶
Aggregating some technical questions we received about this project:
Q: How much time did you spend on "prompt engineering" compared to "flow engineering"?
A: Structured output almost completely eliminates the need for simple prompt engineering. We estimate that ~95% of the time we did more high-level design, reasoning, and injecting data at the correct places, ..., a.k.a. "flow engineering".
Q: How do you know that there wasn't a data leakage?
A: The test set of CodeContests dataset comprises problems published after September 2021, while the GPT-4 model variant we used (gpt-4-0613) has a data cutoff of September 2021. Hence, there is no data leakage for GPT4, on the test set. For other models like DeepSeek, we cannot be sure. However, note that our main result is a comparison of "direct prompt" vs. "AlphaCodium flow". Data leakage would help both approaches, so the relative improvement of AlphaCodium flow is still valid.
{kind=link}
Q: Is this project relevant only to specific programming languages?
A: No. The proposed flow is language agnostic. We generated solutions in Python, but the flow can be applied to any language.
Q: How did you manage the context window?
A: We used models with a context window of 8192 tokens, and we did not encounter cases where it did not suffice. However, we clearly observed that as the context we used in practice grows larger (let's say, above 4000 tokens), the model starts to "ignore" some of the information in the context. Hence, there is a clear tradeoff: - Injecting the results of previous stages into the context, may help the model to generate better code. - However, it may also cause the model to ignore specific details and nuances from the problem description.
Q: Is this work "realistic" in terms of the number of LLM calls?
A: In comparison to AlphaCode, we do four orders of magnitude (!) fewer calls (per solution AlphaCodium does 15-20 calls). Yet we acknowledge that for some applications, this may still be too much, and more optimizations are needed. We however believe that many of the ideas and principles we acquired in this work are broadly applicable, even when the number of calls is further limited.
{kind=link}
Q: Why do you iterate only on the generated code, and not on the AI-generated tests?
A: For code problems in CodeContests, the tests are a list of input-output pairs. Hence, you don't really learn anything new when you "fix" a test - you just change its output to the prediction of the generated code. Instead of fixing tests, we preferred to always try and fix the code, while using "test anchors". (see the paper for more details). However, for other code generation tasks, where the tests are more complex and contain runnable code, iterating on the tests, in addition to iterating on the generated code, may be beneficial.
Broader Applicability¶
While this work presents results on CodeContests dataset, we believe that it has a broader applicability.
First and foremost, we feel that the proposed AlphaCodium flow, with reasonable adjustments, can be used as a more general framework for other code generation tasks.
Secondly, many of the design concepts, principles, and tricks we acquired in this work are broadly applicable as-is to any general code generation tasks. For example: - YAML Structured output: asking the model to generate an output in YAML format, equivalent to a given Pydantic class
-
Semantic reasoning via bullet points analysis: Bullet points analysis encourages an in-depth understanding of the problem, and forces the model to divide the output into logical semantic sections, leading to improved results
-
LLMs do better when generating a modular code: when asking the model to:
divide the generated code into small sub-functions, with meaningful names and functionality, we observe a better-produced code, with fewer bugs, and higher success rates for the iterative fixing stages. -
Soft decisions with double validation: with a double validation process, we add an extra step where, given the generated output, the model is asked to re-generate the same output, but correct it if needed
-
Leave room for exploration: since the model can be wrong, it’s better to avoid irreversible decisions, and leave room for exploration and code iterations with different possible solutions
The list above is partial. See the paper for more details. The code provided in the repo can be used as a reference for better understanding the proposed concepts, and for applying them to other code generation tasks.
Example Problem¶
In this section, we present an example for a full problem from CodeContests dataset (test-set, problem 1), in order to demonstrate the complexity of the problems in the dataset, and the challenges they pose to LLMs.
problem name: '1575_B. Building an Amusement Park'
problem description:
Mr. Chanek lives in a city represented as a plane. He wants to build an amusement park in the shape of a circle of radius r.
The circle must touch the origin (point (0, 0)).
There are n bird habitats that can be a photo spot for the tourists in the park. The i-th bird habitat is at point p_i = (x_i, y_i).
Find the minimum radius r of a park with at least k bird habitats inside.
A point is considered to be inside the park if and only if the distance between p_i and the center of the park is less than or equal
to the radius of the park.
Note that the center and the radius of the park do not need to be integers.
In this problem, it is guaranteed that the given input always has a solution with r ≤ 2 ⋅ 10^5.
Input
The first line contains two integers n and k (1 ≤ n ≤ 10^5, 1 ≤ k ≤ n) — the number of bird habitats in the city and the number of bird
habitats required to be inside the park.
The i-th of the next n lines contains two integers x_i and y_i (0 ≤ |x_i|, |y_i| ≤ 10^5) — the position of the i-th bird habitat.
Output
Output a single real number r denoting the minimum radius of a park with at least k bird habitats inside. It is guaranteed that the given
input always has a solution with r ≤ 2 ⋅ 10^5.
Your answer is considered correct if its absolute or relative error does not exceed 10^{-4}.
Formally, let your answer be a, and the jury's answer be b. Your answer is accepted if and only if \frac{|a - b|}{max{(1, |b|)}} ≤ 10^{-4}.
Examples
Input
8 4
-3 1
-4 4
1 5
2 2
2 -2
-2 -4
-1 -1
-6 0
Output
3.1622776589
Input
1 1
0 0
Output
0.0000000000
Note
In the first example, Mr. Chanek can put the center of the park at (-3, -1) with radius √{10} ≈ 3.162. It can be proven this is the minimum r.
Acknowledgments¶
Our process CodeContests dataset is based on the original CodeContests dataset. We removed the train set (which is not relevant to our work) and did some post-processing and cleaning to the validation and test sets.